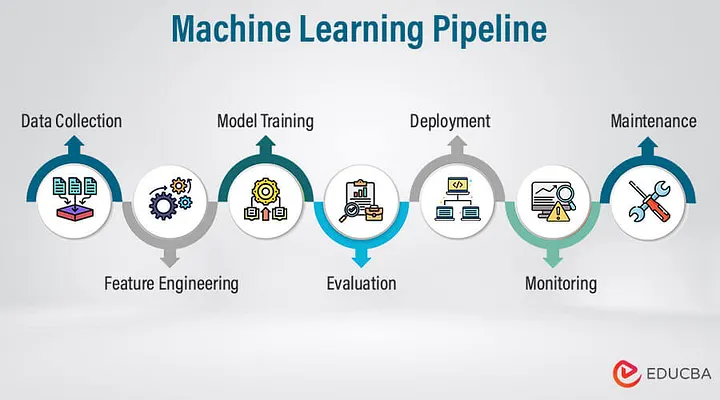
Typische Trainingspipeline:
https://medium.com/@surajagrahari330/machine-learning-pipeline-from-raw-data-to-insightful-models-80c54914b7a9
Die Cloud-Services funktionieren in der Regel als Black-Box-Systeme, d.h. die Auswahl eines konkreten Verfahrens für die Regression oder Klassifikation wird automatisiert vorgenommen, sodass das Verfahren zum Einsatz kommt, welches für den vorliegenden Datensatz am besten geeignet ist.
Beispiel für Regressionsverfahren in der Google Cloud: lineare Regression, multiple lineare Regression, Gradient Boosted Decision Trees (GBDT), …
In diesem Artikel erfahren Sie mehr über die Trainingspipeline für Maschinelles Lernen in der Google Cloud.
Hinweis: Schalten Sie im Artikel in den einzelnen Abschnitten immer auf den Tab “Tabellarisch” um!